
Row Data Now!를 Tim Berners Lee가 소리 높여 외치고
모두에게 이득이 될 수 있는 공공 데이터의 공개 및 이용이 대세가 되어가고 있는 가운데. 글쎄.. 우리 나라는?
내 동생은 프로 스카이다이버.
나는 아마추어 패러글라이더.
둘 다 기상/기상 예보에 민감할 수 없는 상황.
동생은 기상청 날씨 예보가 맞느냐 틀리느냐가 바로 그 다음날, 바로 그 주말의 수입과 직결되기때문에 기상청 예보에 신경을 곤두세우는데..
어느 날 동생 왈. “ㅅㅂ… 기상청 예보 15일 연속 틀렸어. 수퍼컴퓨터는 어디다 쓰는거야”
나의 대답. “아부지한테 최신형 컴퓨터 사준다고 주식거래 잘하게 되는거 아니잖아”
세금으로 수퍼 컴퓨터 사다가 세금으로 기상 정보 수집하면서,
그 데이터를 민간 기관에서 이용하여 날씨 예보를 하는 것이 원천 봉쇄되어 있다고.
왜? 똑같은 raw data를 가지고 실력있는 민간기관에서 기상예보를 하게 되면
같은 데이터를 분석한 결과로 90% 정확도로 일기예보를 하게 될테니 허가해 줄 턱이 없다는것.
뭐 이거야 어디까지나 한 개인의 의견일 뿐이고.
나도 절대적으로 동의한다는건 비밀이지만
어쨌든 사실 관계를 확인하러 한국 기상청 홈페이지에 들어가봤다.

국격 돋는 한국 기상청의 위엄
그랬더니.. 데이터를 공개는 하고 있지만, 늬들이 가져다 쓰는건 불법이고
(수익을 내지 않으면 괜찮다지만, 결국 민간 기업이 데이터 가지고 일기 예보 하지 말라는 얘기잖아 ㅋㅋㅋ)
이거 가지고 앱 만들고 싶다는 요청이 을매나 많았으면
ㅅㅂ 이거 늬들 앱 만들라고 공개하는 데이터 아니거든? 꺼져 주실래? 라고 저렇게 ㅋㅋㅋㅋ
게다가 그나마 2013년 상반기중으로 이런식의 raw data 공개도 안하시겠단다.
빅데이터 가지고 이놈의 나랏님이 뭘 하시길 바라것어…
아참, 이런 말 하면 종북 좌파 빨갱이지 -_-;
혹시 기상청에서 보면 명예 회손으로 고소하시려나~
1장. 빅데이터란 무엇인가?
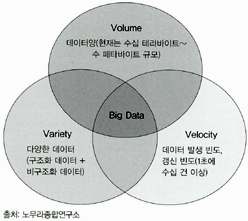
빅데이터의 특성을 나타내는 3V
고객과 기업 사이의 인터랙션 데이터를 분석하면 트랜잭션이 발생한 이유를 알 수 있다. 지금까지 인터넷(온라인)의 인터랙션 데이터 수집/분석을 중요시했지만, 앞으로는 오프라인 및 O2O (Online to Offline)의 인터랙션 데이터가 중요해질 것이다.
2장. 빅데이터의 기반이 되는 기술
Hadoop
하둡이란 오픈소스로 공개된 대규모 데이터의 분산처리 기술이다. 특히 빅데이터 시대에 필요한 대량의 비구조화 데이터 처리 성능이 뛰어나고, 비용이 저렴하며, 스케일 아웃으로 용량 증가에도 대응하기 쉽다는 점에서 주목받고 있다. 하둡은 구글이 2004년에 발표한 ‘맵리듀스: 대형 클러스터의 데이터 처리 단순화’라는 대규모 데이터의 분산처리에 관한 논문이 기반이 되었다.
맵리듀스와 하둡의 관계에 대해 보충하자면, 맵리듀스는 분산처리라는 ‘처리방식’이고 하둡은 맵리듀스를 오픈소스로 구현한 ‘프레임워크’이다.
‘맵리듀스’라고 했을 때는 단순히 ‘처리방식’을 가리키므로 구현 형식이 꼭 하둡이라고만은 할 수 없다.
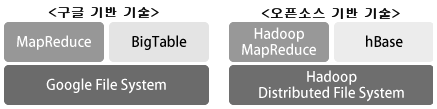
구글과 오픈소스 기반 기술의 대응관계
원래 하둡은 대용량 파일을 분할해 저장하는 HDFS9Hadoop Distributed File System)라는 분산파일 시스템과 대량의 데이터를 효율적으로 분산처리 할 수 있는 Hadoop MapReduce, 그리고 HBase라는 초거대 데이터테이블, 이렇게 세 가지로 구성되어 있다.
데이터 처리 관점에서 중요해진 것이 구글의 논문 중 맵리듀스를 프로그램으로 구현한 ‘Hadoop MapReduce’이다. ‘Hadoop MapReduce’는 고성능 CPU와 저장장치가 탑재된 컴퓨터가 아닌 일반 컴퓨터 여러 대를 나열해 구성한 클러스터로 대규모 데이터를 분산 처리하는 프레임워크다.
NoSQL
NoSQL 데이터베이스에는 ‘데이터 구조가 단순하다’, ‘스키마 정의가 불필요(또는 유연하게 변경가능)하다’, ‘데이터의 일관성이 엄밀하게 유지되지 않는다’, ‘스케일아웃으로 높은 확장성을 실현할 수 있다’는 특징이 있다. 간단히 말해 NoSQL은 데이터의 일관성을 다소 희생하는 대신 유연성, 확장성을 추구한 데이터베이스라고 할 수 있다.
Complex event processing
스트림 데이터 처리에서는 입력된 데이터를 하드디스크에 기록하지 않고 메모리에서 데이터 처리가 이루어지므로 빠른 속도로 처리할 수 있다. 또한 바로 직전에 처리한 결과를 중간 데이터로서 가지고 있어 데이터를 모두 처리할 필요가 없으며, 메모리에 흘러가는 데이터에서 중간 데이터와의 차이가 난 데이터양 만큼만 처리하면 된다. 이런 방식으로 입력에서 결과 출력까지의 지연 시간을 1/100만 초 수준까지 낮추고 1초당 수십만 건부터 수백만 건의 초고속 처리를 실현한다.
3장. 빅데이터를 무기로 활용하는 미국과 유럽 기업
EBay
– EBay에는 세가지 분석 플랫폼이 있다. ‘기술적으로 문제 해결의 묘책은 없다(There is no technology silver bullet)’라고 생각하기 때문이다. 어느 기술에나 일장일단이 있기 때문에, EDW나 Hadoop만 사용하는 것보다 세가지 기술을 상호보완적으로 조합해야 가장 좋다는 것이다.
– 표본데이터가 아니라 전체 데이터를 대상으로 분석하는 것, 즉 빅데이터 활용 효과를 단적으로 얻을 수 있다는 의미
– 이베이에서는 각 기술의 특성을 정확히 평가하고 쓰임새를 냉정하게 파악해서 구현한다.
4장. 빅데이터를 무기로 활용하는 일본 기업
하둡의 장점
> 일괄처리로 대표할 수 있는 처리 시간 증가에 대한 대책
> 로그 기반으로 데이터 관리를 일원화
> 머하웃 등의 에코시스템을 사용해 분석 엔진이나 추천 엔진을 빠르게 구현할 수 있다> 고속 처리를 할 수 있으므로 조건을 바꿔 몇번이라도 시행착오를 반복해도 괜찮다.
> 샘플링에 의존하지 않는 롱 테이블 부분의 분석이 가능하다.
> 개발 주기를 단축할 수 있다.많은 데이터를 고속으로 처리할 수 있다는 하둡의 기술적 관점도 중요하지만, 오히려 그 이상의 장점은 하둡을 사용하면 지금가지 할 수 없었던 일을 할 수 있을 것 같다고 느끼게 되고, 분석/상품 기획을 하는 사람의 의식을 변화시켜 무의식중에 체념하던 발상의 벽을 없앤다는데 있지 않을까요?
GREE가 성장한 원동력은 기업 문화에 깊이 배어있는 ‘한 개인의 감성보다 수천만 명의 데이터를 믿는 데이터 주도형 접근’에 있다.
5장. 빅데이터 활용 패턴
빅데이터 활용 유형의 분류
> 개별 최적화/전체최적화
> 일괄처리형/실시간처리형
reCAPTCHA is a free CAPTCHA service that helps to digitize books. 구글은 또 한가지 사용 목적이 서적의 디지털화에 있음을 숨기지 않고 설명하는 것이다.
6장. 빅데이터 시대의 개인정보보호
Do Not Track
Opt in vs Opt out
개인 정보의 정의 – (EU) ‘데이터 주체’에 관한 정보를 의미하는 것. 이 ‘데이터 주체’에는 위치정보나 IP, 쿠키를 의미하는 ‘온라인 식별자’를 포함한다. 일본 개인정보 보호법은 이름, 생년월일등 특정 개인을 식별할 수 있는 것을 대상으로 하며 위치정보나 IP, 쿠키등은 포함하지 않는다. 이처럼 ‘개인정보’의 적용 대상이 다른 점에는 주의할 필요가 있다.
웹 페이지의 행동 이력은 열람 이력이나 구매 이력 등이 상당한 정도로 축적되면 개인의 관심사, 기호, 정치적 성향 등을 미루어 짐작할 수 있으므로 개인의 내면처럼 비밀성이 높은 정보라고 생각할 수 있다 또한 위치정보도 상당 기간에 걸쳐 시간 순서로 연결되면 개인의 생활이 드러날 가능성이 크다. 따라서 이런 정보는 타인에게 함부로 알려지고 싶지 않다고 생각하는 것이 자연스럽다. 그러므로 웹 페이지의 행동 이력이나 위치정보는 취급 양상에 따라서 사생활에 관계되는 정보로서 법적 보호 대상이 될 가능성이 있다.
EU에서는 미국과는 대조적으로 ‘사용자의 명확한 동의 없이 개인정보 데이터를 처리해선 안된다’는 옵트인 방식의 대응을 요구하고 있어, 온라인 광고 회사 등이 맹렬히 반대하고 있다.
7장. 오픈 데이터 시대의 시작과 데이터 마켓플레이스의 등장
LOD (Linked Open Data)
Row Data Now! – Tim Berners-Lee
Data.gov/에서는 정부 데이터가 국민의 자산이라는 사고 방식을 바탕으로 연방정부 기관이 소유한 raw data catalog와 Geo data catalog를 제공한다.
Data.gov는 공공기관의 적극적인 데이터 공개가 혁신으로 이어진다고 보고, 미국 내부의 시와 주에 그치지 않고 다른 나라 정부에도 머신리더블 형태의 데이터를 공개할 것을 호소하고 있다.
(일본) 무엇보다 문제인 것은 공개된 데이터의 파일 형식이 머신 리더블 형태가 아닌 PDF나 MS EXCEL형식이라는 점이다. 결국 Tim Berners-Lee가 주창했던 LOD운동에는 맞지 않는다.
마켓플레이스에 따라 데이터 형식이나 용어가 제각각이다. 이는 서로 다른 마켓플레이스에서 구한 데이터를 조합하려고 했을 때 큰 문제가 된다. 각각의 데이터는 원래 다른 데이터와 조합해 사용하는 것을 예상해서 설계된 것이 아니다. 이때문에 메타데이터등도 충분히 부여하지 않은 사례가 많다.
구글에서는 이런 과제에 대한 대책의 하나로 데이터를 메타데이터와 함게 유지하고 자유롭게 시각화할 수 있는 DSPL이라는 XML언어를 개발했지만 아직 널리 보급되지 않았다.
8장. 빅데이터 시대의 준비
빅데이터 활용에 맞는 조직 체제와 기업 분위기 확립
고품질 데이터 확보, 데이터를 효율적으로 처리할 수 있는 IT인프라 구축, 우수한 데이터 과학자 확보가 이루어졌다고 한다면 마지막으로 해결할 문제는 조직 체제와 기업 분위기 확립니다. 아무리 우수한 분석 결과를 얻을 수 있다고 해도 정확한 의사 결정과 신속한 행동으로 연결될 수 있는 조직체제가 없으면 쓸모없어져 버린다. 경험이나 직감과는 다른 분석 결과가 나왔을 때 무조건 경험이나 직관을 우선하는 기업 분위기라면 의미가 없기 때문이다.
데이터 주도형 기업
데이터 주도형 기업으로 가는 길은 그리 간단하지 않다. 일부 분석팀이나 경영층만이 아닌 사원 누구나 대량의 데이터에 접근할 수 있는 환경의 정비, 분석 결과를 바로 비즈니스로 구현할 수 있는 조직 편성 등 검토해야 할 사항이 여러 갈래에 걸쳐 있기 때문이다.
빅데이너란 단순히 데이터양의 증가만을 가리키는 것이 아니다. 지금까지 활용하지 않았던 또는 활용할 수 없었던 다양한 데이터를 적절히 수집해가면 결과적으로 많은 데이터가 되기는 할 것이다. 하지만 반드시 데이터양이 꼭 수십 테라바이트 페타바이트에 달할 필요는 없다. 중요한 것은 이제까지 무시했던 데이터의 가치를 깨닫는 것이다.
0 Comments.